普段、私たちが使っている「文字」は、コンピュータの内部ではすべて数値(文字コード)で表現されています。たとえば「A」も「あ」も「吉」も、実はそれぞれ異なる文字コードを持っています。
ところが、Unicodeの世界には「2バイトでは表現できない文字」も存在します。その代表例が、絵文字(emoji)や「下側の線が長い吉」のような文字です。
これらの文字を扱うために生まれたのが「サロゲートペア(surrogate pair)」という仕組み。
この記事では、サロゲートペアの意味・仕組み・具体例、そしてUnicodeコードポイントからUTF-16への変換方法などを図を用いてわかりやすく解説します。
サロゲートペアとは?
サロゲートペア(surrogate pair)とは、UTF-16で表現できる文字数の上限(U+FFFF)を超えた文字を、4バイト(2つの16ビット値)で表す仕組みです。このサロゲートペアが使われるのはUnicodeのU+10000以降(U+10000~U+10FFFF)にある文字であり、絵文字や一部の漢字、特殊記号などがこれに該当します。
もう少し詳しく説明します。
UTF-16は、Unicodeの文字を16ビット(=2バイト)単位で表現する文字コード方式です。
UTF-16では、通常1文字を2バイトで表現します。2バイトだと0x0000~0xFFFF(=約6万5千通り)の値を表せるため、当初はこの範囲で世界中の文字を網羅しようというのがUnicodeの構想でした。
日本語でも同様に、全角・半角に関係なく1文字あたり2バイトを使用します。たとえば「a」も「あ」も2バイトです。そのため、「文字数 × 2 = 使用バイト数」という関係が常に成り立ち、使用バイト数を2で割れば簡単に文字数を求められるという利点がありました。文字列を1文字ずつ処理するプログラムを書くときにも便利でした。
しかし、Unicodeに含めたい文字が年々増え、2バイトでは文字が足りない状況になりました。とはいえ、すべての文字を4バイトに拡張すると、それまでUTF-16を利用していたシステムに影響が出てしまうため、「基本は2バイトのまま、一部の文字だけ4バイトにする」という仕組みが採用されました。この4バイト1文字で表される文字が「サロゲートペア」です。
サロゲートペアでは、従来使われていなかったUnicodeの0xD800~0xDFFF領域を利用します(この領域は通常の文字には使われないように予約されていました)。0xD800~0xDBFF(1024通り)を「上位サロゲート(high surrogate)」、0xDC00~0xDFFF(1024通り)を「下位サロゲート(low surrogate)」と定義し、この2つを組み合わせた「上位サロゲート+下位サロゲート」で1文字を表現します。
この仕組みにより、1024×1024=1,048,576(約100万)文字分の新しい領域が追加されました。
つまり、サロゲートペアは「UTF-16の互換性を維持したまま、Unicodeの文字数上限を大幅に拡張するための仕組み」です。
サロゲートペアの具体例
実際にどのような文字がサロゲートペアで表現されているのか、具体例を見てみましょう。
絵文字
サロゲートペアのその代表的な例が、絵文字(emoji)です。たとえば、以下のような絵文字はすべてサロゲートペアによって表現されています。
| 絵文字 | 上位サロゲート | 下位サロゲート | UTF-16表現 | Unicode コードポイント |
|---|---|---|---|---|
| 😀 | U+D83D | U+DE00 | D83D DE00 | U+1F600 |
| 😂 | U+D83D | U+DE02 | D83D DE02 | U+1F602 |
| 😍 | U+D83D | U+DE0D | D83D DE0D | U+1F60D |
| 😎 | U+D83D | U+DE0E | D83D DE0E | U+1F60E |
| 😭 | U+D83D | U+DE2D | D83D DE2D | U+1F62D |
| 🙏 | U+D83D | U+DE4F | D83D DE4F | U+1F64F |
これらの絵文字は、上位サロゲート(U+D83D)と下位サロゲート(U+DE00〜U+DE4F)の2つを組み合わせて1文字として扱われます。つまり、UTF-16ではこのような絵文字は「4バイト」を使って表現されているのです。そのほかにも、以下のような絵文字もサロゲートペアで表現されています。
サロゲートペアで表現している絵文字
😁 | 😃 | 😄 | 😅 | 😆 | 😇 | 😈 | 😉 | 😊 | 😋 | 😌 | 😏 | 😐 | 😑 | 😒 | 😓 | 😔 | 😕 | 😖 | 😗 | 😘 | 😙 | 😚 | 😛 | 😜 | 😝 | 😞 | 😟 | 😠 | 😡 | 😢 | 😣 | 😤 | 😥 | 😦 | 😧 | 😨 | 😩 | 😪 | 😫 | 😬 | 😮 | 😯 | 😰 | 😱 | 😲 | 😳 | 😴 | 😵 | 😶 | 😷 | 😸 | 😹 | 😺 | 😻 | 😼 | 😽 | 😾 | 😿 | 🙀 | 🙁 | 🙂 | 🙃 | 🙄 | 🙅 | 🙆 | 🙇 | 🙈 | 🙉 | 🙊 | 🙋 | 🙌 | 🙍 | 🙎
ただし、すべての絵文字がサロゲートペアというわけではありません。たとえば「☹(U+2639)」や「☺(U+263A)」といった昔からある絵文字はUTF-16では1つの16ビット値(2バイト)で表されます。
JIS第1水準・JIS第2水準に含まれない文字
JIS第1水準・JIS第2水準に含まれない文字を下表に示します。
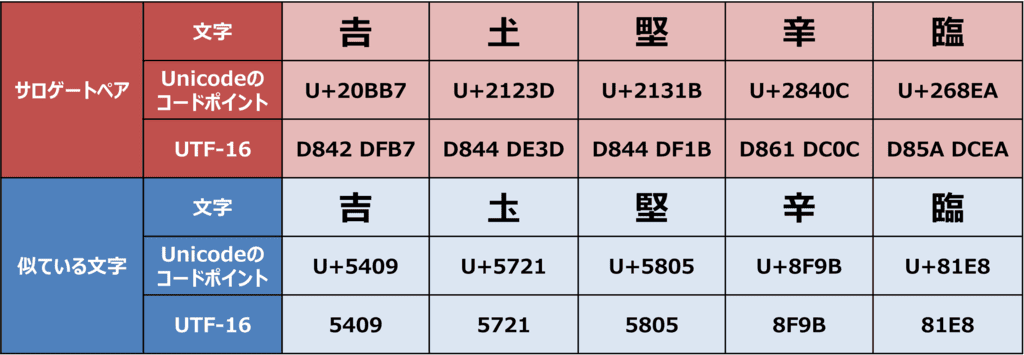
サロゲートペアは、絵文字だけでなく、JIS第1水準・JIS第2水準に含まれない漢字などでも使われます。例えば、下側の線が長い「吉」のような文字です。
以下のサイトでは、入力した文字がどのようなコードで表現されているのかを調べられます。
例えば、上記のサイトに、下側の線が短い「吉」と下側の線が長い「吉」を入力してみると、次のように違いが確認できます。
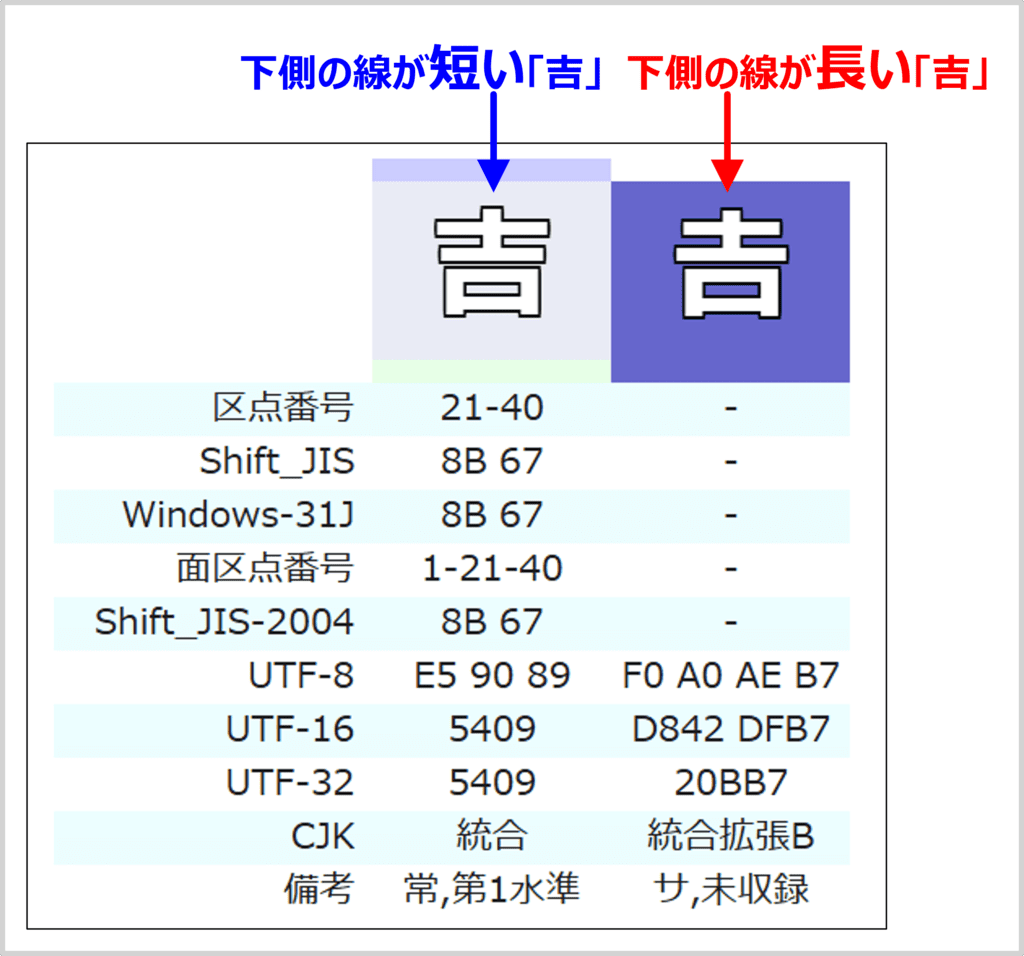
下側の線が長い「吉」はWeb上で表示できない環境も多いため、下側の線が長い「吉」と記載しています。
下側の線が短い「吉」と下側の線が長い「吉」のそれぞれの文字コードが表示されています。最下行「備考」の欄に、下側の線が長い「吉」は「サ,未収録」と表示されていますが、この「サ」がサロゲートペアであることを示しています。下側の線が長い「吉」は「句点番号」や「Shift JIS」では表現できず、「UTF-8」や「UTF-16」では正しく表現することができます。
まとめると、下側の線が長い「吉」は以下のように表現されます。
| 種類 | 値(16進) |
|---|---|
| 上位サロゲート(High Surrogate) | 0xD842 |
| 下位サロゲート(Low Surrogate) | 0xDFB7 |
| UTF-16表現 | D842 DFB7 |
| Unicodeコードポイント | U+20BB7 |
| HTML表記 | 𠮷 |
HTMLでサロゲートペアの文字を表示する方法

HTMLでは、「&#x」+(Unicodeの16進数)+「;」と書くことで、Unicodeの文字コードから直接文字を表示することができます。
例えば、「あ(Unicode: 0x3042)」を表示したい場合、あとHTMLに書きます。
同じ方法で、サロゲートペアを使う文字も表示できます。例えば、下側の線が長い「吉」( Unicode: 0x20BB7)の場合、𠮷とHTMLに書きます。
Javascriptでサロゲートペアの文字を表示する方法
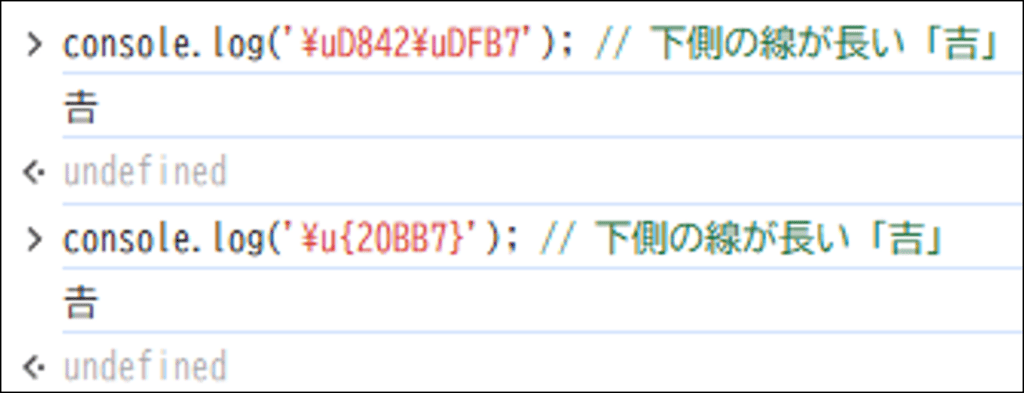
JavaScriptでも、Unicode文字を直接出力することができます。下側の線が長い「吉」( Unicode: 0x20BB7)のようなサロゲートペア文字も扱えます。
JavaScriptの文字列リテラルでは、\uXXXXの形式を使うと、UTF-16で1つの文字を指定できます。しかし下側の線が長い「吉」はサロゲートペア(4バイト)なので、2つの\uXXXX指定で構成します。
// 「下側の線が長い『吉』」をUTF-16で出力する例
console.log('\uD842\uDFB7'); // 下側の線が長い「吉」ECMAScript 2015(ES6)以降では、\u{}という新しい形式でUnicodeコードポイントを直接指定できます。これにより、サロゲートペアを意識せずに書けるようになりました。
// Unicodeコードポイントで直接指定(ES6以降)
console.log('\u{20BB7}'); // 下側の線が長い「吉」サロゲートペアの文字コードは「5桁」だけどデータは「4バイト」
UTF-16では、通常1文字を2バイト(16ビット)で表現します。そのため、従来のUnicode文字コードは「4桁の16進数(例:U+3042)」で表記されていました。
一方、サロゲートペアの文字は4バイト(32ビット)で表現されます。「4バイトなら、文字コードも8桁の16進数になるのでは?」と思われるかもしれませんが、Unicodeコードポイントは5桁(例:U+20BB7)の形で表記されます。
これは、サロゲートペアのUnicodeコードポイントが独自の変換規則に従って4バイトに分解される仕組みになっているためです。つまり、「サロゲートペアの文字は、文字コードは5桁だけど、実際のデータは4バイト」というぐらいで理解しておいてください。
| 種類 | 例 | Unicodeコードポイント | 実際のバイト数 |
|---|---|---|---|
| 通常のUnicode文字 | 「あ」 | U+3042 | 2バイト |
| サロゲートペア文字 | 下側の線が長い「吉」 | U+20BB7 | 4バイト |
では変換手順を、実際の計算過程(U+20BB7をUTF-16のD842 DFB7に変換する)と一緒に見てみましょう。
UnicodeコードポイントからUTF-16への変換方法
手順①:0x10000 を引く
まず、下側の線が長い「吉」のUnicodeコードポイントU+20BB7から0x10000を引きます。
0x20BB7 - 0x10000 = 0x10BB7この結果をX = 0x10BB7とします。
手順②:Xを0x400(=1024)で割る
次に、X = 0x10BB7を0x400で割ります。
0x10BB7 ÷ 0x400 = 商 0x42、余り 0x2B7- 商(
0x42)は「上位サロゲート」計算に使います - 余り(
0x2B7)は「下位サロゲート」計算に使います
手順③:上位・下位サロゲートを求める
それぞれに基準値を足します。商(0x42)には0xD800に足します。これを「上位サロゲート」とします。余り(0x2B7)には0xDC00に足します。これを「下位サロゲート」とします。
| 名称 | 計算式 | 結果 |
|---|---|---|
| 上位サロゲート | 0xD800 + 商(0x42) | 0xD842 |
| 下位サロゲート | 0xDC00 + 余り(0x2B7) | 0xDFB7 |
手順④:上位+下位の順に並べる
上位サロゲート → 下位サロゲートの順で並べると、UTF-16のD842 DFB7になります。これが、下側の線が長い「吉」( Unicode: 0x20BB7)の4バイト表現です。
本記事のまとめ
この記事では『サロゲートペア』について説明しました。
サロゲートペアは、UTF-16の世界で「2バイトでは表せない文字」を扱うための仕組みです。基本的な文字(あ・A・漢字など)は2バイトで表現できますが、絵文字や一部の漢字などの文字は「4バイト=サロゲートペア」で表現されます。
これを理解しておくと、「なぜ一部の文字が文字化けするのか」「なぜ文字数カウントがずれるのか」といったトラブルの原因も見えてきます。
お読みいただきありがとうございました。