AIやチャットボットの話題で『RAG』という言葉を見かけることがあります。
「そもそもRAGって何?」「普通の生成系AI(LLM)と何が違うの?」と疑問に思っている方も多いのではないでしょうか。
この記事では『RAG』について、以下の内容を図を用いてわかりやすく解説します。
- RAGとは?
- RAGの仕組み
- RAGのメリットとデメリット
- RAGの活用例
- RAGとLLMの違い
RAGとは?
RAGは「Retrieval-Augmented Generation(検索拡張生成)」の略で、「検索(Retrieval)」と「生成(Generation)」を組み合わせたAIモデルです。
たとえば、LLM(GPT、Claude、Geminiなどの通常の生成系AI)は、大量のデータを事前に学習し、その知識をもとに回答を生成します。そのため、「学習した時点までの知識」しか持っていません。つまり、モデルの作成後に出てきた新しい情報や、企業内の社内データ、最新の専門的研究などは、基本的に理解していません。こういった情報を取り込むには、AIを一から再学習させる必要があり、大きな手間とコストがかかります。
そこで登場するのがRAGです。RAGは、質問を受け取ったときに、外部情報(例:社内ドキュメント、論文データベース、ナレッジベース、特定のインターネットリソースなど事前に接続・設定された対象)を検索して、関連する情報を集め、その情報をもとにAIが回答を作ります。これにより、最新の情報や、AIが学習していない内容にも対応できるようになり、より正確な回答が期待できます。
LLMは「Large Language Model」の略で、日本語では『大規模言語モデル』と呼ばれています。
RAGの仕組み
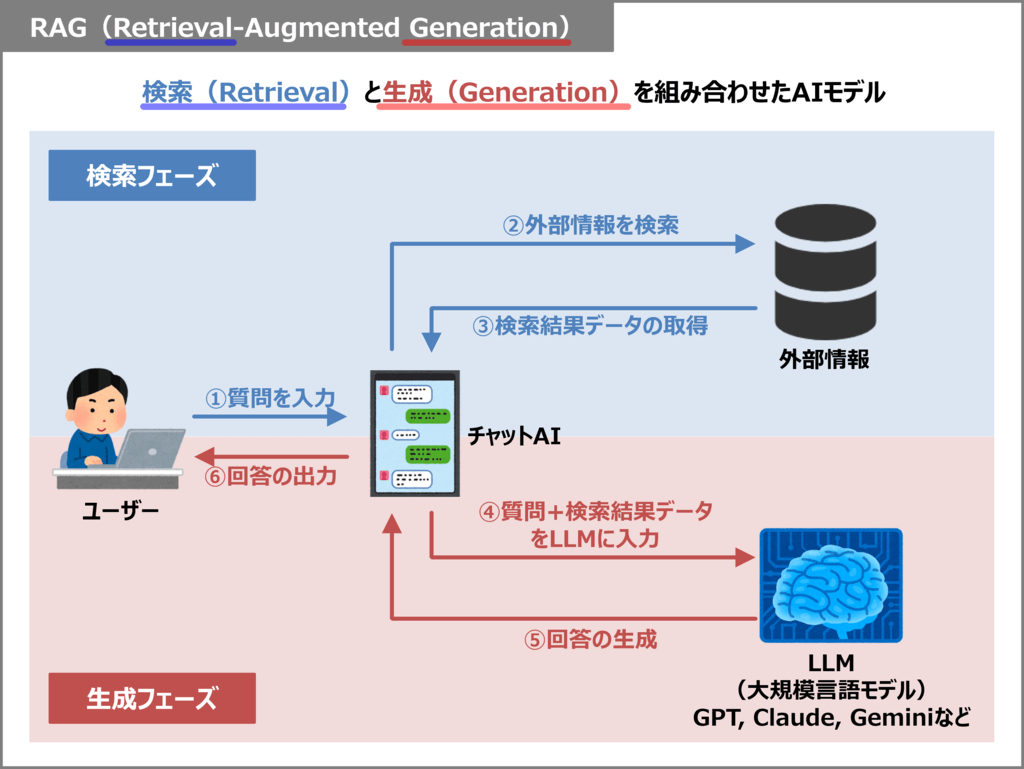
RAGはユーザーからの質問に対して、「検索(Retrieval)」と「生成(Generation)」の2つのフェーズを経て回答を生成します。上図の概念図を参考に、仕組みを説明します。
検索(Retrieval)フェーズ
検索フェーズでは、ユーザーの質問に対して最適な回答ができるよう、外部情報を検索してデータを収集します。
- ① 質問を入力
- ユーザーがチャットAIに質問を入力します(例: 最新のAI技術について教えて!)
- ② 外部情報を検索
- チャットAIが内部で、外部情報を対象に検索を行います。
- ③ 検索結果データを取得
- 検索結果を取得します。
生成(Generation)フェーズ
生成フェーズでは、検索フェーズで得たデータをもとに、LLMが回答を生成します。
- ④ 質問+検索結果データをLLMに入力
- チャットAIは質問と検索結果を組み合わせ、LLM(大規模言語モデル)にプロンプトとして渡します。
- ⑤ 回答の生成
- LLMは、渡された情報をもとに自然な回答を生成し、チャットAIに返します。
- ⑥ 回答の出力
- チャットAIはLLMから得た回答を、ユーザーに表示します。
この「検索(Retrieval)」と「生成(Generation)」の2つのフェーズを組み合わせることで、通常の生成系AI(LLM)では出せない最新かつ信頼性の高い回答が可能になります。
RAGのメリットとデメリット
RAGのメリットとデメリットを以下に示します。
メリット
- 最新情報にアクセスできる
- モデルを作った後に発生したデータも、検索で取り込める。
- 専門知識のカバー範囲が広がる
- モデル単独では難しい医療、法律、研究など専門性の高い質問にも外部情報を対象に検索を行うことで回答可能。
- モデルサイズを無理に増やさなくて良い
- 全知識をモデル内部に詰め込む必要がない
デメリット
- 検索精度に依存する
- 関連性の低いドキュメントを拾ってしまうと、誤った回答になるリスクがある。
- 応答速度が遅くなる場合がある
- 検索のステップがある分、応答速度が遅くなることがある。
- 検索対象の品質管理が必要
- 外部データに誤情報や古い情報が含まれていると、それを基に間違った回答をしてしまう。
RAGの活用例
RAGはさまざまな分野で活用されています。
- 社内QAシステム
- 社内ドキュメント、手順書、FAQを検索して、社員の質問に答える。
- 医療分野の診断補助
- 医学論文やガイドラインを参照して、医師の判断をサポートする。
- 学術研究・調査支援
- 学術データベースや論文を横断検索して、関連情報や要約を提示する。
- ニュース要約・記事生成
- 複数のニュースを集めて、要点をまとめて自動生成する。
- カスタマーサポートのAIチャット
- 製品マニュアルやよくある質問を検索して、お客さまからの問い合わせに自動で答える。
RAGとLLMの違い
RAGは、従来のLLM(大規模言語モデル)に「外部データを検索して使う」という新しい仕組みを加えた技術です。では、具体的にどこがどう違うのか、LLM単体とRAGを比較してみましょう。
| LLMのみ(生成AI単体) | RAG(検索拡張生成) | |
| 知識の範囲 | 学習時点までの知識しか使えない | 外部のデータも使える(検索して活用) |
| 最新情報への対応 | 再学習しないと取り込めない | 外部データを更新すればすぐ使える |
| 専門・ニッチな情報への対応 | 学習されていなければ答えられない | 外部の専門情報を引っ張ってこられる |
| 再学習の必要性 | 新しい情報の対応には再学習が必要 | 基本的に不要(データを入れ替えるだけ。ただし検索対象や構成によっては調整が必要な場合もある) |
| 向いている場面 | 雑談や一般的な知識を使う場面 | 医療・法律・社内情報など、正確で最新情報が必要な場面 |
本記事のまとめ
この記事では『RAG』について、以下の内容を説明しました。
- RAG(Retrieval-Augmented Generation)は「検索」と「生成」を組み合わせたAIモデル。
- 通常のLLM(大規模言語モデル)は学習時点までの知識しか持たない。
- RAGは質問に応じて外部データを検索し、その情報を使って回答を生成する。
- 最新情報や社内・専門データにも対応可能なのが大きな特徴。
- 仕組みは2段階:「①検索(Retrieval)→②生成(Generation)」
- メリット
- 学習後の新しい情報も使える
- 専門性の高い情報にも対応
- モデルを巨大化させなくて良い
- デメリット
- 検索精度に依存する
- 応答が遅くなる場合がある
- 検索対象のデータ品質が重要
- 活用例
- 社内QA、医療診断支援、論文調査、ニュース要約、カスタマーサポートなど
- RAGとLLMの違い
- RAGは外部データを検索して使えるため、より正確で最新の回答が可能。
お読み頂きありがとうございました。